Slice Studios
Lead-generation and website automation platform for selling websites to independent restaurants — scrape Google Maps, spot weak or missing sites, and spin up demos from their real menu and hours.
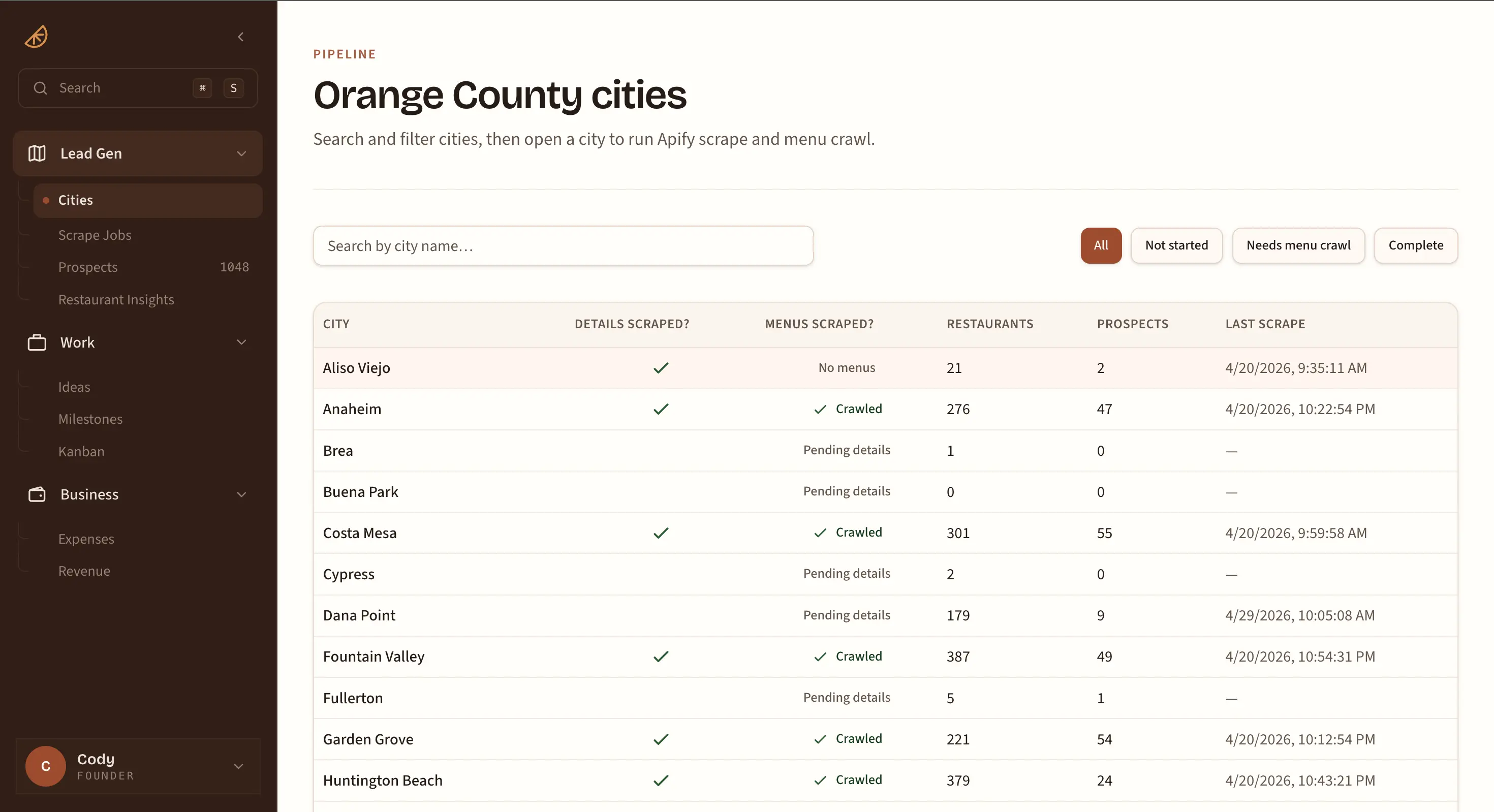
Overview
Slice Studios is a micro-SaaS and sales automation platform built for a local web design business targeting independent restaurants in Orange County, CA. The full pipeline runs Prospect → Demo → Sell → Onboard → Maintain: Google Maps is scraped via Apify to discover restaurants, each is classified by its current web presence, and qualifying targets are enriched with their real data to auto-generate personalized demo sites. After a sale closes, onboarding is fully automated — Vercel project provisioned, domain assigned, Twilio webhook activated — and clients maintain their site by texting changes via SMS/WhatsApp, which an LLM parses and applies directly to the CMS.
Highlights
Scraping & Classification Pipeline
- Apify Integration: Triggers Google Maps scrapes by Target City + Search Category (e.g. "taquerias in Anaheim"), with idempotency records preventing duplicate runs
- Firecrawl Crawling: Crawls existing restaurant websites to extract structured content used during enrichment
- Website Classification: Each restaurant is labeled
no_website,facebook_only,instagram_only,yelp_only,ordering_platform_only,basic_placeholder, orhas_website— only the first six are sales targets - Job Scheduler: Postgres-backed scrape job table with task/restaurant counts, cancellation support, and startup recovery for interrupted jobs
Automated Demo Generator (in progress)
- LLM Enrichment: Transforms raw scraped data — Google Maps info, review highlights, Firecrawl page content — into structured content ready to populate a demo site
- Cuisine-Specific Templates: Three pre-built Next.js templates (taqueria, pizza, Asian) with per-cuisine schema extension fields; taquerias are the first POC
- Payload CMS Backend: A dedicated
apps/cmsworkspace powered by Payload v3 stores editable restaurant and menu records linked to the scraper database byrestaurantId, with drafts/versions and public read access for published content - One-Click Demo Preview: Demo sites are generated from Template + Enrichment output and served for in-person sales visits, pre-populated with the prospect's real name, hours, menu, and photos
Automated Onboarding & Maintenance (planned)
- Vercel Provisioning: On sale close, a Vercel project is created and a domain is assigned programmatically via the Vercel API
- Twilio Webhook: A WhatsApp/SMS webhook is activated per client; incoming texts are parsed by an LLM, mapped to CMS field updates, and trigger a Vercel revalidation — no client portal needed
- Welcome Flow: Automated welcome message sent to the new client with their site URL and instructions
Internal Dashboard
- Restaurant browser with filters, sorting, and full-text search across all scraped data
- Prospect queue with per-restaurant disposition tracking and outreach status
- City management with per-city scrape and crawl job controls
- Scrape job monitor with live progress, cancellation, and error visibility
- Business views for revenue, expenses, milestones, and a Kanban work board
- Keyboard shortcuts and command palette via TanStack Hotkeys
Tech Stack
Frontend: React 19, TypeScript, Vite 7, Tailwind CSS v4, shadcn/ui, TanStack Query v5, React Router v7, nuqs, dnd-kit
Backend: Express 4, TypeScript, Drizzle ORM, Neon PostgreSQL (serverless), Better Auth (email/password + passkeys), Apify client, Firecrawl JS SDK, Resend + React Email
CMS: Payload v3 (apps/cms), Next.js, Payload Postgres adapter, drafts/versions, public-read access control
Planned: Vercel API (automated project provisioning), Twilio (SMS/WhatsApp webhook), OpenAI (enrichment + message parsing)
Architecture: pnpm monorepo, feature-sliced backend (routes → controller → service → Drizzle), Zod-validated environment config and request schemas, centralized error classes
Engineering Decisions
- Scraping costs money; analysis is free — raw records are stored permanently so classification and enrichment can be re-run without new Apify jobs
- Custom over off-the-shelf — the job scheduler, classification logic, and prospect pipeline are hand-rolled for portfolio value and full control
- Payload as the CMS layer — editable demo content lives in a separate Payload database, keeping the scraper's Drizzle schema as the source of truth for prospect data while Payload owns publishable restaurant/menu content
- No client portal — post-sale maintenance is handled entirely via SMS/WhatsApp + LLM, keeping the client experience dead simple
- Portable tooling — Neon, Drizzle, Better Auth, and Payload keep the stack ownable with no proprietary vendor lock-in
